Last Updated on 7 June 2023 by admin
Table of Contents
In previous posts, we have looked at how to identify potential phishing attempts which may contain malicious URLs that can harvest your credentials. Recent attacks against Microsoft, Facebook, and Twitter have all used specially crafted URLs to phish customers and employees. These attacks have been extremely successful and further proves humans are the weakest element in security. But what can be done to prevent these attacks aside from user education?
This post briefly outlines how machine learning can be used to identify a malicious phishing links simply by looking at its vocabulary and a selection of other features. The research project was conducted as part of Informer’s ongoing refinement of phishing simulations to help clients gain a more valuable engagement.
Here is the code for this project
Getting started with the right data
Before beginning any machine learning project, it is imperative to find a good dataset that contains enough data points to meaningfully train the model and provide accurate and reliable results. For this project, a dataset provided on Kaggle has been used. This dataset contains over 500,000 entries and will be perfect for training the model.
Define the data features
The dataset contains URLs and labels saying whether they have been verified to be malicious (bad) or not (good), but to actually train the model we need to extract useful information (features) from the data the machine learning model will be able to understand. This raises the question of what constitutes a malicious link? To help visualize this, we can get a sample from the dataset:
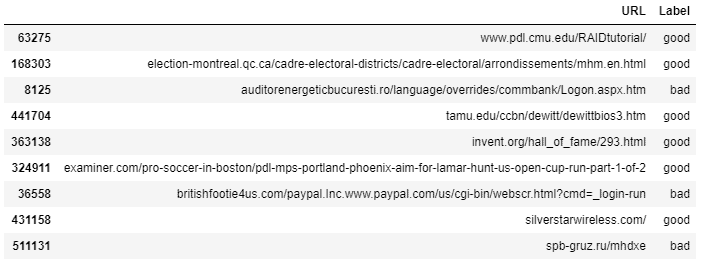
From this data, several features may come to mind. Firstly, looking at the Top Level Domain (TLD) of the URL can be useful. Normally the top-level domain will be Com or Co.uk, but malicious links may contain rarer extensions such as Ru or Ro in this case. There may also be safer extensions such as gov or edu. Additionally, the length of the URL and the number of subdomains present may be useful indicators of whether or not the domain is malicious. Perhaps most importantly, the actual words present in the URL such as Exe or Cmd may instantly indicate a malicious link. We will be able to confirm these hypotheses in the feature importance section below.
For the pre-processing steps, we need to extract the features we want the model to use and any text needs to be converted into a numerical format for the model to understand. To do this, we first need to tokenize the URL to get each individual word, then use a vectorizer to change the text into numerical values. This will greatly increase the number of features of the dataset.
Selecting the right machine learning model
To pick a model we first must know what type of problem we are trying to solve. There are hundreds of machine learning models each with certain types of problems it excels at. The problem we are currently working with is a classification problem, more specifically binary classification (good or bad URL). Some models which are great at these are as follows:
Each has its own benefits and drawbacks, and all will be tested and compared to see which performs best.
Training the model
Each model was trained on 80% of the dataset, with the remaining 20% reserved for testing after the model has been trained. One of the shortcomings of Support Vector Machines (SVMs) is that they do not scale well with high amounts of data, with training often taking upwards of 5 hours on our data. However, using a linear kernel with SVMs results in a reasonable training time of under a minute.
Feature importance
The graph below shows the most important features in the model. The positive weights indicate important features of good URLs whereas the negative ones show important features of malicious ones. Each word of the URL has been created into its own feature and we can see mostly what words are most important in a URL.

The word PayPal seems to be related to a lot of malicious URLs, possibly used in attempts to trick people into thinking it is legitimate. This could be seen as a limitation of this approach as normal PayPal links may seem malicious. The TLD gov has been shown to be a sign of good URLs, likely because they have to be specifically applied for through a government, similarly, Edu and Ac.uk domains must be specifically applied for. Interestingly, the length of a URL and the number of subdomains is a big factor in malicious URLs, where some path punctuation is related to good URLs.
And the winner is?
From the test data, the three models achieved the following accuracy scores:
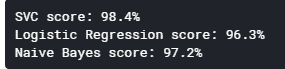
As we can see from the results, the Linear SVC model achieved the highest accuracy at over 98%. This means that this model produced the lowest number of false positives and false negatives (recall and precision) and can be considered the best model for this problem out of the three. The graph below shows the confusion matrix for the SVC model. Confusion matrices show what each data point was predicted as against its true value.
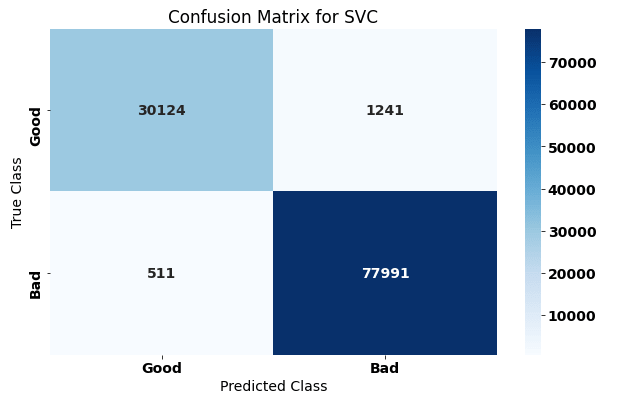
Further testing found that some of the features extracted reduced the overall accuracy score for logistic regression, so removing these ended up providing the best results. The Naive Bayes model reported more false negatives (URLs that were reported as good but were actually bad) more often than both other models, and logistic regression predicted more false positives than both other models.
Future work & limitations
Regardless of the model, achieving around 97% accuracy for predicting malicious URLs simply by looking at the URL itself is impressive. But as previously mentioned, the fact words such as PayPal relate to malicious URLs may mean that PayPal’s legitimate URLs could be classified as malicious. To combat this, a check against the Alexa top sites could be performed to filter out common sites which may be trusted. This is a list of the most frequently visited sites and therefore most sites present are not malicious.
Additionally, the chosen models assume features are independent of one another, i.e. each feature of the data does not affect any others. This is often not the case with real-world data and some of the features may be better predictors on the condition that other features are present. It would be interesting to explore how features are dependent on each other and possibly develop a more comprehensive model.
A further check may be on the actual content of the web page itself. This would need to be done carefully to ensure no execution of malicious code occurs, but viewing the URL for other links or certain phishing characteristics would further enhance the accuracy of the model.